Projekt: Sezonowość pytań rolników w Afryce Wschodniej (2019–2020)
Narzędzia: Python (pandas), Tableau, Excel / Power Query
Opis: Analiza wielojęzycznych pytań rolników (WeFarm) w celu identyfikacji powtarzalnych wzorców sezonowych w obszarach upraw, chorób roślin, nawożenia i cen rynkowych.
Cel: Zrozumienie cykli aktywności i potrzeb informacyjnych rolników oraz przełożenie ich na wnioski operacyjne (planowanie treści, kampanii i komunikacji w odpowiednim czasie).
Dane: Zanonimizowane dane, udostępnione w ramach DataKind challenge; w repozytorium brak surowych danych.
Repozytorium:  Zobacz na GitHub
Zobacz na GitHub
Wprowadzenie
Pytania zadawane przez rolników drobnotowarowych zawierają informacje nie tylko o bieżących problemach, ale także o sezonowych cyklach pracy, produkcji i zapotrzebowania na wiedzę. Projekt powstał w ramach wolontariatu analitycznego DataKind – Producers Direct DataKit Challenge i był dla mnie okazją do przeanalizowania wieloletnich danych w sposób uporządkowany, transparentny i nastawiony na identyfikację wzorców.
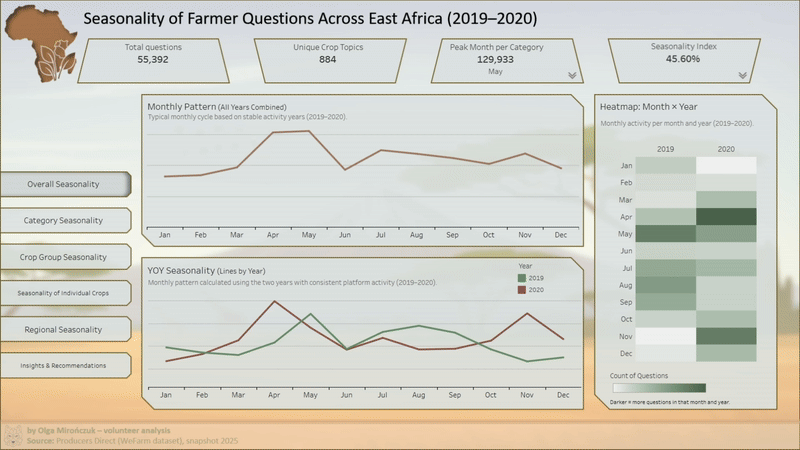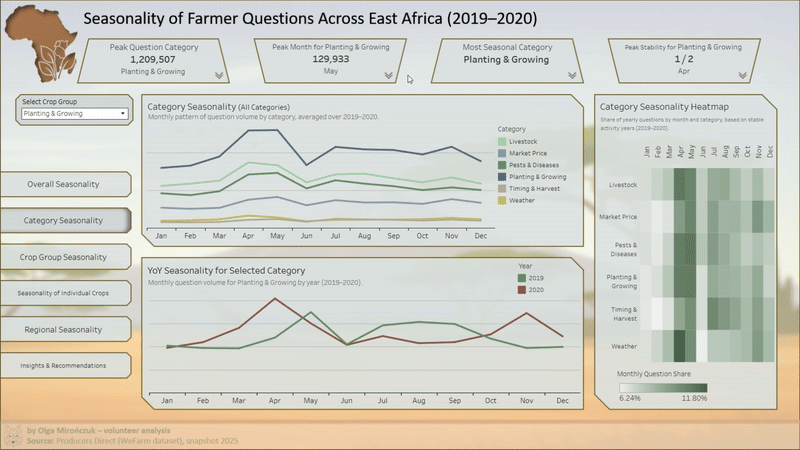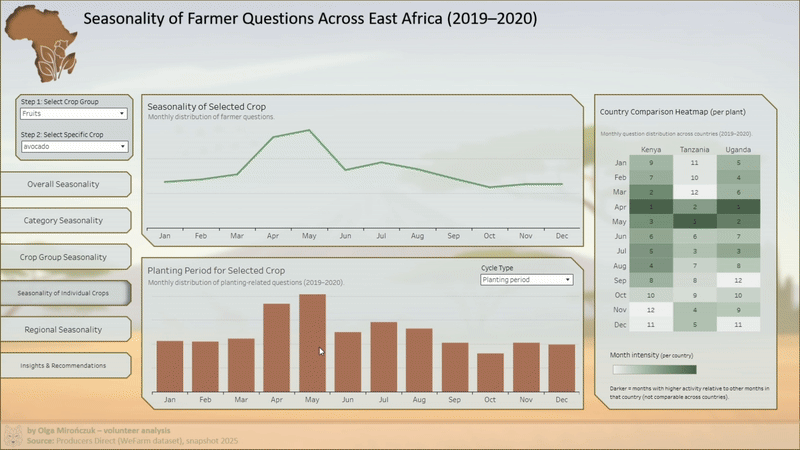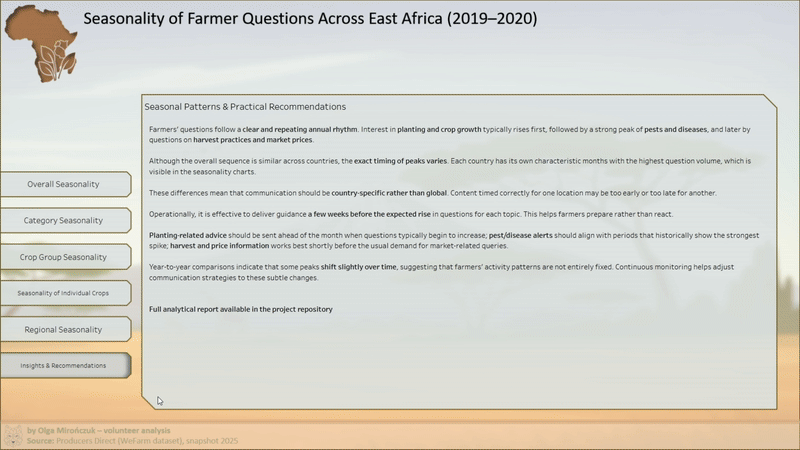
Dashboard miał pokazywać sezonowość nie jako pojedyncze piki aktywności, lecz jako powtarzalne schematy: kiedy rolnicy pytają o sadzenie, choroby roślin, nawożenie czy ceny rynkowe, jak te potrzeby zmieniają się w ciągu roku oraz czym różnią się między regionami. Zależało mi na wizualizacji spokojnej i czytelnej. Analizie, która pomaga zrozumieć rytm danych i kontekst operacyjny, a nie upraszcza zjawiska do jednego wskaźnika. Projekt obejmował zarówno pracę koncepcyjną, jak i pełny proces przygotowania danych oraz budowę narzędzia analitycznego.

Certyfikat DataKind potwierdzający udział w międzynarodowym projekcie wolontariackim z zakresu analizy danych.
Dane
- Zakres analizy: 2017–2024 (z uwzględnieniem różnej kompletności lat)
- Źródło danych: zanonimizowane dane WeFarm udostępnione uczestnikom DataKind challenge przez Producers Direct.
- Dane miały postać tabelaryczną i obejmowały m.in.:
- identyfikatory rekordów,
- znaczniki czasowe (rok, miesiąc),
- informacje o kraju i języku,
- krótkie pytania rolników w formie tekstowej,
- techniczne metadane platformy.
Kluczowym elementem analizy były treści tekstowe, wymagające dalszej klasyfikacji tematycznej. Zgodnie z zasadami DataKind dane źródłowe oraz tabele wynikowe (agregacje) nie są publicznie udostępniane. Repozytorium zawiera kod analityczny, dokumentację procesu oraz artefakty pomocnicze wykorzystywane w pipeline’ie.
Proces
1) Przygotowanie i klasyfikacja danych (Python)
- Dane zostały przetworzone w Pythonie z wykorzystaniem notebooków dokumentujących kolejne etapy pipeline’u.
- Najważniejsze kroki:
- oczyszczenie i standaryzacja pól czasowych,
- kontrola spójności metadanych (kraje, języki),
- przygotowanie treści tekstowych do klasyfikacji,
- budowa i iteracyjna rozbudowa słownika semantycznego,
- pół-automatyczna klasyfikacja tematyczna (human-in-the-loop),
- przygotowanie danych do agregacji sezonowej.
- Efektem pipeline’u była zagregowana tabela typu pivot (metryka: liczba pytań), wykorzystywana następnie jako źródło danych w Tableau. Plik z pivotem nie jest publicznie udostępniany; w repozytorium znajduje się opis jego struktury oraz procesu tworzenia.
- Ze względu na wielojęzyczność danych i brak pełnych zasobów tłumaczeniowych analiza nie opierała się na tłumaczeniu wszystkich treści na jeden język, lecz na wzorcach częstotliwości i czasie występowania tematów.
2) Wizualizacja (Tableau)
- Dashboard został zaprojektowany jako narzędzie interpretacyjne, a nie raport statyczny.
- Struktura obejmuje:
- przegląd ogólnej aktywności i wolumenu pytań,
- sezonowość kategorii tematycznych w ujęciu miesięcznym,
- porównania regionalne,
- podsumowanie kluczowych wzorców i możliwych zastosowań operacyjnych.
- Wykorzystane elementy:
- KPI opisujące skalę i sezonowość,
- wykresy trendów miesięcznych,
- heatmapy (miesiąc × rok),
- interaktywne filtry (czas, region, kategoria),
- tooltipy objaśniające kontekst i ograniczenia danych.
- Układ i kolorystyka zostały dobrane z myślą o czytelności i porównywalności, bez nadmiernego akcentowania pojedynczych miesięcy czy kategorii.
Wyniki
- Analiza ujawniła m.in.:
- wyraźne, powtarzalne wzorce sezonowe dla kluczowych tematów,
- różnice w rytmie zapytań między regionami,
- koncentrację pytań dotyczących sadzenia i chorób w określonych okresach roku,
- potencjał wykorzystania sezonowości do planowania komunikacji i treści doradczych.
- Dashboard umożliwia analizę tych wzorców w czasie oraz zestawianie ich między kategoriami i regionami, bez dostępu do danych źródłowych.
Refleksje
- Największym wyzwaniem była praca z danymi tekstowymi w wielu językach, a nie sama wizualizacja. Kluczowe znaczenie miały:
- jasne definicje kategorii,
- świadome decyzje metodologiczne,
- ręczna kontrola jakości klasyfikacji.
- Projekt wymagał ciągłego balansowania między szczegółowością a czytelnością. Zamiast maksymalnej precyzji w każdym punkcie, priorytetem była spójność procesu i możliwość interpretacji wyników przez osoby nietechniczne. Analiza miała wspierać decyzje operacyjne, a nie tworzyć narrację opartą na pojedynczych ekstremach.

 Ciasteczko do kawy?
Ciasteczko do kawy?